
Empezamos a utilizar Delta Live Tables (DLT) de Databricks a principios de este año, cuando se hizo compatible con Unity Catalog. Creímos que estaba lo suficientemente maduro como para empezar a utilizarlo de verdad, y en este artículo voy a compartir nuestras experiencias hasta ahora con su uso para el procesamiento por lotes.
DLT es el propio marco de transformación optimizado de Databricks que funciona tanto con datos en flujo como por lotes. Es muy cómodo porque rastrea automáticamente los datos que aún no se han cargado y se encarga de toda la orquestación de tareas. Todo lo que tienes que hacer es definir las transformaciones desde las tablas de entrada hasta las tablas de salida, y DLT se encargará de averiguar las dependencias y el orden de ejecución.
Puedes hacerlo utilizando SQL con simples sentencias CREATE TABLE AS SELECT (CTAS). Sin embargo, DLT realmente destaca cuando se utiliza Python. Admite canalizaciones programadas imperativamente, lo que significa que puedes definir y trabajar con cientos de tablas mediante bucles a través de la configuración y/o directorios de conjuntos de datos por etapas.
Esta introducción solo araña la superficie, pero hay muchos recursos que te ayudarán a empezar. Consulta estos enlaces para obtener más información:
Caso de uso
Uno de nuestros clientes del sector del comercio electrónico se encuentra en medio de una importante revisión y ha trasladado la mayoría de sus servicios a soluciones SaaS como Salesforce. Intervinimos para construir su Lakehouse mientras su nueva configuración de comercio electrónico estaba en marcha. Esto significaba que nuestras fuentes de datos cambiaban constantemente, con nuevas tablas y columnas que se añadían, actualizaban y eliminaban a diario. Aquí es donde DLT destaca. Puede gestionar automáticamente la creación de nuevas tablas y hacer evolucionar los esquemas sin ningún tipo de ingeniería, o al menos con una ingeniería muy mínima en comparación con un enfoque no DLT. Este artículo describe cómo utilizamos DLT para minimizar nuestros esfuerzos de ingeniería.
Nuestra configuración
Para este proyecto, utilizamos una configuración estándar de Azure:
- Cuentas de almacenamiento en Azure: tienen un espacio de nombres jerárquico y contienen tanto datos organizados como tablas gestionadas por Unity Catalog.
- Fábrica de datos: se encarga de la carga de datos y la orquestación de alto nivel, como la copia de datos y el inicio de canalizaciones y trabajos DLT de Databricks.
- Databricks: se encarga de todo lo demás: permisos en Unity Catalog, transformaciones de datos mediante DLT y flujos de trabajo, análisis con SQL, etc.
- Otros servicios: también utilizamos Key Vaults, Log Workspaces, componentes de red, etc., pero no son el centro de atención aquí.
A continuación, se describe la arquitectura de datos y los componentes utilizados.
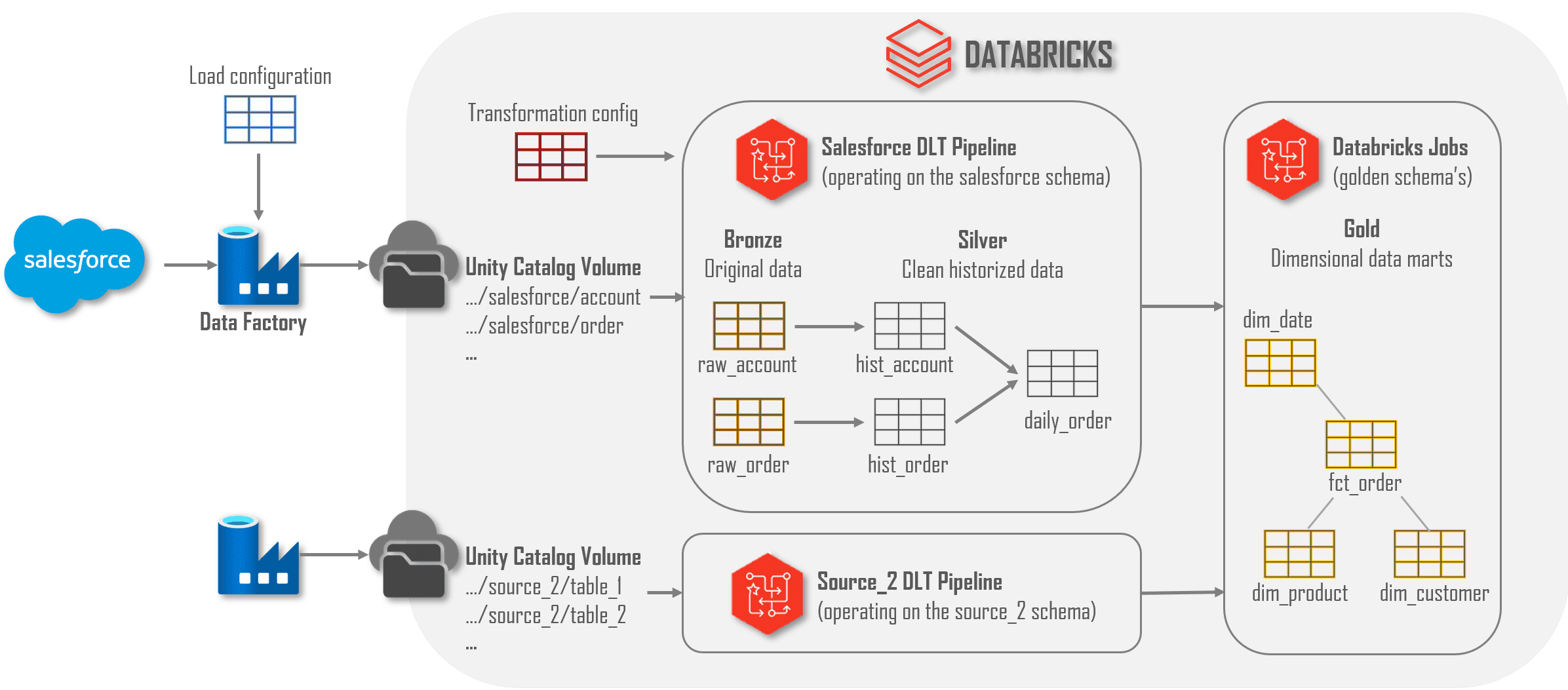
A continuación, te mostramos un desglose de nuestra arquitectura de datos y sus componentes:
- Carga de datos con Data Factory:
- Data Factory copia todas las tablas y conjuntos de datos de origen en un volumen de Databricks según su configuración. Nos encargamos de gestionar las tablas y columnas de origen dentro de la configuración, no del código.
- Todos los datos copiados por Data Factory se escriben en un almacenamiento Datalake asignado a un Volumen de Catálogo Unity.
- Creación de Tablas Bronce y Plata con DLT:
- Una canalización DLT crea tablas bronce y plata para cada directorio que encuentra en una ubicación específica del Volumen de almacenamiento. Así, cuando ADF configura y copia una tabla de origen adicional, la canalización DLT la recoge automáticamente y crea tablas para ella utilizando la evolución de esquemas.
- Una configuración adicional dentro de la canalización DLT se encarga de transformaciones específicas, sobre todo para datos PII (trataremos esto en otro artículo).
- Crear conjuntos de datos dorados con Databricks:
- Los trabajos de Databricks crean conjuntos de datos dorados, que en su mayoría son marts de datos tabulares. Las columnas de las tablas plata (preagregadas) se integran en hechos y dimensiones utilizando terminología empresarial en lugar de nombres específicos del sistema fuente.
- Mientras que las capas bronce y plata están algo desgobernadas (cargamos lo que obtenemos), la capa dorada está estrictamente gobernada para garantizar datos de alta calidad para los consumidores. La mayoría de los objetos de la capa dorada son VISTAS SQL, que son fáciles de mantener y no requieren recarga tras los cambios. Si el rendimiento o los costes se convierten en un problema, podríamos materializar esas tablas doradas, pero por ahora, preferimos la flexibilidad que proporcionan las vistas.
En concreto, describiremos cómo cargamos los datos de Salesforce, pero esa es solo una de las fuentes que tenemos. Todas se cargan siguiendo los mismos patrones, aunque las transformaciones que utilizamos para limpiar los datos varían en función de la fuente o incluso de la tabla.
Data Factory
Los datos de Salesforce se copian en Datalake por medio de Data Factory. El pipeline de Salesforce carga primero la configuración necesaria mediante una acción LookUp. Cada registro de esta configuración contiene toda la información necesaria para copiar el delta de un único objeto de Salesforce e incluye el nombre del objeto, las columnas que se van a incluir, el directorio de destino en el lago y la fecha y hora en que se cargó el objeto por última vez.
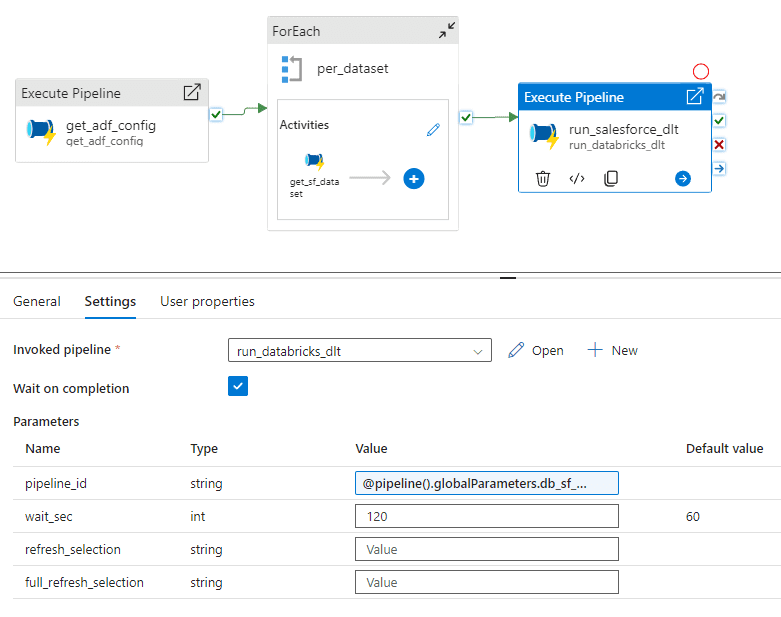
Para añadir un objeto a Lakehouse (tablas bronce y plata), solo es necesario añadir un registro a esta tabla de metadatos con una marca de tiempo de última carga de 2000-01-01 para asegurarnos de que obtenemos todos los registros. Si se quiere modificar una tabla existente, por ejemplo añadiendo o eliminando columnas que se quieran copiar, se hace de la misma manera. Cada vez que se ejecuta esta canalización, copia los nuevos datos de cada objeto configurado en el Datalake en una ruta como ecom-raw/salesforce/_load_ts=yyyy-MM-ddT… (particionada según la fecha y hora de carga). Una vez copiados todos los objetos, Data Factory inicia la canalización DLT. Hemos creado canalizaciones ADF para orquestar canalizaciones y trabajos DLT de Databricks que aprovechan la API de Databricks.
A continuación se muestra toda la canalización ADF para cargar los datos de Salesforce.
Canalización DLT
Nuestros canales DLT están configurados para cargar todas las tablas de una única fuente en las capas de bronce y plata. Esto significa que cada fuente tiene su propio esquema dentro de Unity Catalog, donde opera la canalización DLT. Aunque esta configuración es clara y organizada, tiene el inconveniente de que no nos permite realizar transformaciones entre distintos sistemas de origen (es decir, integración de datos). Hasta ahora, esto no ha supuesto un problema importante, pero puedo prever situaciones en las que podríamos necesitar cargar y combinar varios sistemas de origen dentro de una única canalización DLT (y, por tanto, esquema) en el futuro.
El proceso comienza con la lista de todos los directorios dentro de la ubicación ecom-raw/salesforce/ en el Datalake. Para cada directorio que se encuentra, se crea un conjunto de tablas de flujo. La captura de pantalla que aparece a continuación muestra la lógica principal utilizada para crear las tablas sin procesar e históricas. En las secciones siguientes se ofrecen más detalles.
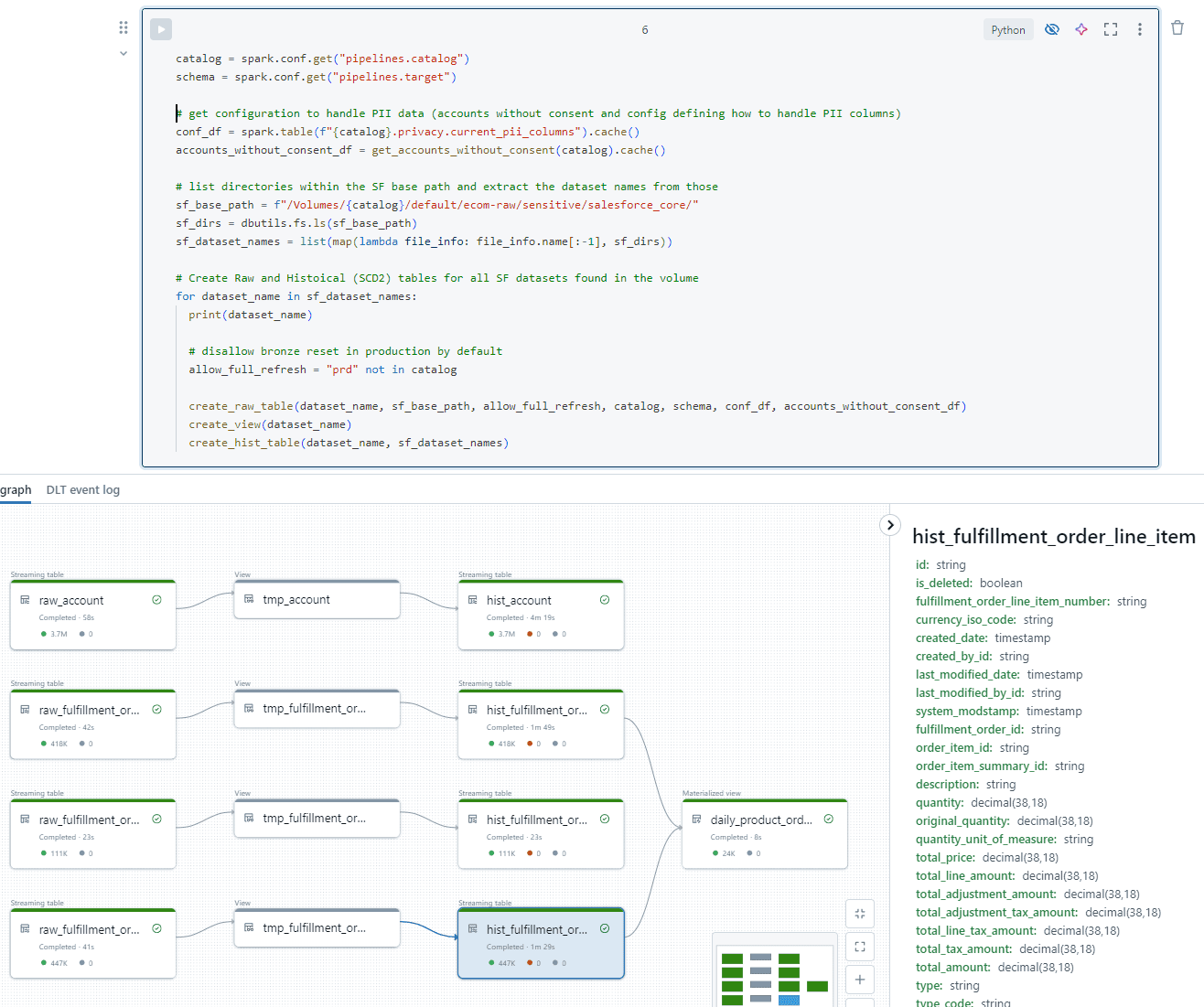
Para cada directorio se crearán los siguientes objetos:
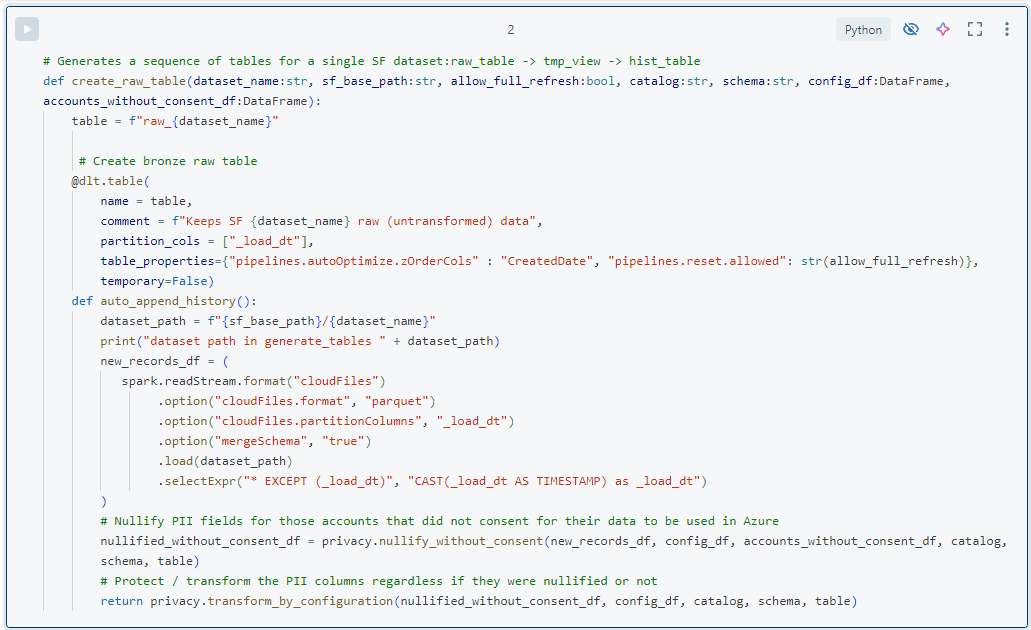
- Una tabla raw_ de bronce, utilizando el autoloader configurado para permitir la evolución del esquema y utilizando la partición _load_ts. Estas tablas tienen el esquema de la fuente y aplican cambios de esquema no rupturistas. Por tanto, es posible añadir y eliminar las tablas y columnas de Salesforce que queramos en Data Factory, que son gestionadas automáticamente por la canalización DLT. No es necesario crear primero las tablas, lo que facilita su gestión.
- Mantenemos la mayor parte del código en módulos separados de Python y los utilizamos en todo el proceso DLT. Los cuadernos contienen principalmente el código @dlt requerido por DLT, pero no la lógica de transformación.
- Por defecto, no alteramos los datos al cargarlos en las tablas de bronce, excepto en el caso relacionado con la privacidad y los campos PII. Mantenemos una tabla de configuración que enumera todos los campos PII y especifica qué hacer con ellos (anularlos, enmascararlos, cifrarlos, etc.). Este marco de metadatos se aplica en la capa de bronce y se explicará en otro artículo.
- La tabla de bronce alimenta una vista DLT ‘tmp_‘, donde aplicamos las transformaciones de limpieza necesarias. Para Salesforce, esto suele ser mínimo, pero, en el caso de otros sistemas de origen que proporcionan datos anidados, los aplanamos o realizamos otras operaciones de limpieza para facilitar el uso de los datos. Esta vista solo existe dentro de la canalización DLT y ayuda a gestionar transformaciones complejas dividiéndolas en pasos separados. En esta vista, podemos incluir comprobaciones de la calidad de los datos para evitar que se carguen datos defectuosos en la capa plateada. Un ejemplo típico es comprobar si la columna ‘rescued_data‘ es null, que indica un conflicto de esquema. En general, adoptamos un enfoque liberal respecto a la calidad de los datos y no bloqueamos la carga de registros a menos que estemos seguros de que algo va mal. Aunque comúnmente se entiende que la calidad de los datos debe definirla el productor, nos parece que esto puede ser demasiado estricto. ¿Por qué bloquear registros basándose en una columna que puede que ni siquiera utilice ningún consumidor?
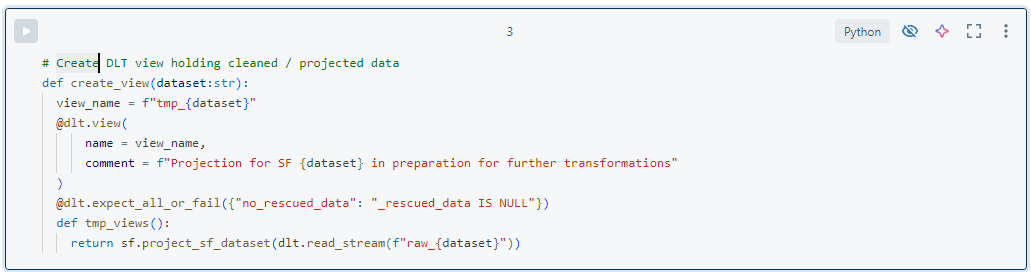
- La tabla de destino se utiliza para la historización de datos limpios y se modela como una dimensión de cambio lento de tipo 2 (SCD2) en tablas ‘hist_‘. En otras palabras, cada registro tiene una columna __START_AT y __END_AT que indican cuándo fue válido. Todos los registros con __END_AT IS NULL son válidos actualmente. Para mantener estas tablas se utiliza la función DLT aplicar cambios. Para ello, necesitamos las columnas de clave de negocio y secuencia, que son muy estáticas en los datos de Salesforce Core. Para otras fuentes, mantenemos esta información en los metadatos.
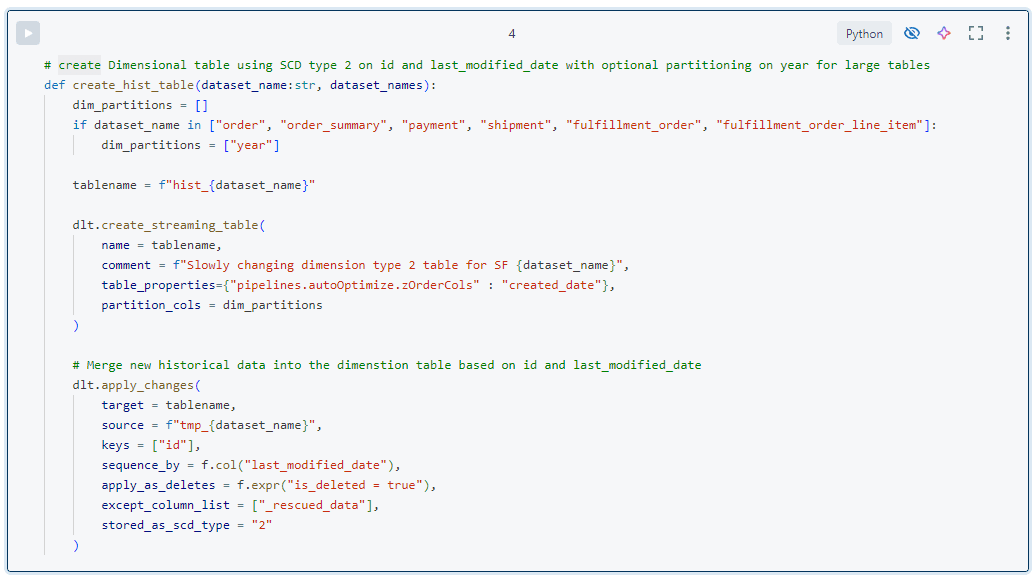
- Dentro de la capa de plata se pueden crear tablas de agregación adicionales uniéndolas y agregándolas. El objetivo es proporcionar datos útiles para determinados grupos de consumidores, como los científicos de datos. Un ejemplo es la agregación de productos por país y día. Este tipo de tabla podría considerarse de oro, pero como no traducimos los datos a terminología empresarial, la consideramos de plata.
Nuestra configuración ha sido sólida. Los cambios realizados en las tablas de origen se recogen automáticamente y se historizan en la capa plateada, lo que facilita el acceso a los consumidores. Añadir tablas de fuentes existentes es tan solo cuestión de configuración, sin necesidad de codificación. En los últimos meses, hemos añadido docenas de tablas a petición de las empresas. Aunque introducir los campos necesarios en los marts de datos requiere cierto trabajo y despliegue, todo el proceso hasta la capa plateada se automatiza mediante la configuración. Esto ha acelerado significativamente nuestra capacidad para proporcionar información adicional. La DLT nos ha servido muy bien hasta ahora, pero eso no significa que no haya inconvenientes u observaciones interesantes que compartir.
Observaciones y lecciones aprendidas
En general, creo que la DLT es muy valiosa, principalmente porque automatiza y normaliza los procesos para reducir la carga de ingeniería y los costes asociados. Los cambios de esquema se gestionan automáticamente y los cambios de datos, como la anulación de campos de información personal, pueden propagarse fácilmente mediante DLT. No es necesario realizar manualmente sentencias UPDATE o DELETE en varias tablas: La DLT se encarga de todo.
Dado que utilizamos muchas tablas de transmisión en lugar de vistas materializadas, las operaciones en una tabla de bronce requieren una actualización completa de las tablas descendientes. Esto puede resultar caro con grandes conjuntos de datos, pero también lo son las horas de ingeniería necesarias para crear trabajos que hagan lo mismo. Creemos que hay opciones para que esto sea menos costoso, como consumir feeds de cambios en lugar de la propia tabla de flujo. Databricks también está trabajando duro para optimizar estos escenarios con innovaciones como el motor enzima y la computación sin servidor.
Desarrollar y probar DLT se ha vuelto más fácil este año porque Databricks ha integrado la vista de cuaderno con la vista de DLT. Ahora puedes ejecutar pipelines DLT e inspeccionar su gráfico de ejecución mientras trabajas en el código. Aunque es práctico, tiene algunos inconvenientes, como la imposibilidad de ver información de depuración impresa. Según mi experiencia, es mejor empezar a desarrollar utilizando el «cálculo normal» y depurar todas las funciones antes de empezar a trabajar con DLT en «modo DLT».
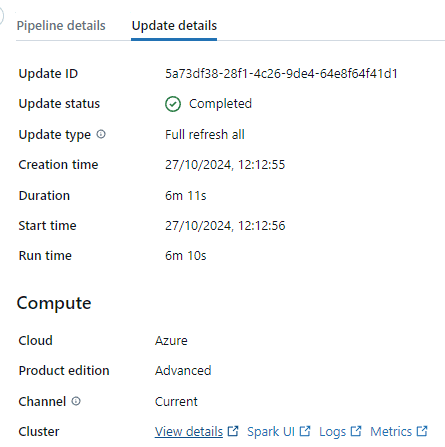
Para el desarrollo, la configuración DLT permite que el clúster esté en modo «Desarrollo», lo que significa que no finaliza tras una ejecución DLT (a diferencia del modo Producción). Esto es estupendo para el desarrollo, pero el tiempo de apagado automático es de dos horas o algo así, por lo que cada ejecución que inicies te costará dos horas extra de «no uso» del clúster. Que yo sepa, no se puede cambiar este tiempo de apagado automático. Sin embargo, puedes encontrar el clúster que utiliza DLT en la sección «Actualizar detalles» de la vista DLT y cerrarlo manualmente para ahorrar costes (ver captura de pantalla más abajo). Esto es algo que todo el mundo debería hacer, pero Databricks no lo pone fácil. Otra forma de evitar este problema es utilizar Serverless Compute, que, según mi experiencia, se «apaga» y se «enciende» con bastante rapidez.
Poca gente sabe que las canalizaciones DLT «reclaman» las tablas que crean. Esto significa que no es posible realizar ciertas operaciones, como restaurar una versión histórica, en las tablas DLT. Además, no es posible que varias canalizaciones DLT trabajen en las mismas tablas. Aunque esto tiene sentido, puede causar problemas cuando varias personas trabajan en las mismas canalizaciones. No es posible «clonar» un proceso para hacer pruebas. Para evitarlo, cada desarrollador puede tener su propia base de datos de desarrollo y esquemas para DLT, o alternativamente, trabajar en la misma canalización DLT en momentos diferentes. Sea cual sea el enfoque, es importante gestionar los permisos sobre el canal para permitir que otros trabajen en él.
La evolución de esquemas es una función fantástica, pero su comportamiento en DLT puede resultar un poco extraño. Cada vez que una ejecución DLT detecta uno o varios cambios de esquema, cancela su ejecución, termina su clúster e inicia una nueva ejecución para realizar la actualización del esquema. La primera vez que me encontré con estas ejecuciones «canceladas», me quedé realmente perplejo, pero hay entradas de registro que explican lo que ocurre. Una de nuestras fuentes produce montones de pequeños archivos JSON (miles al día) que cambian frecuentemente de esquema. Como la inferencia del esquema JSON solo examina 1000 archivos de forma predeterminada, hemos visto casos en los que la tubería se reiniciaba varias veces seguidas para gestionar los cambios. Afortunadamente, existe una opción para cambiar este valor predeterminado, que es spark.databricks.cloudFiles.schemaInference.sampleSize.numFiles.
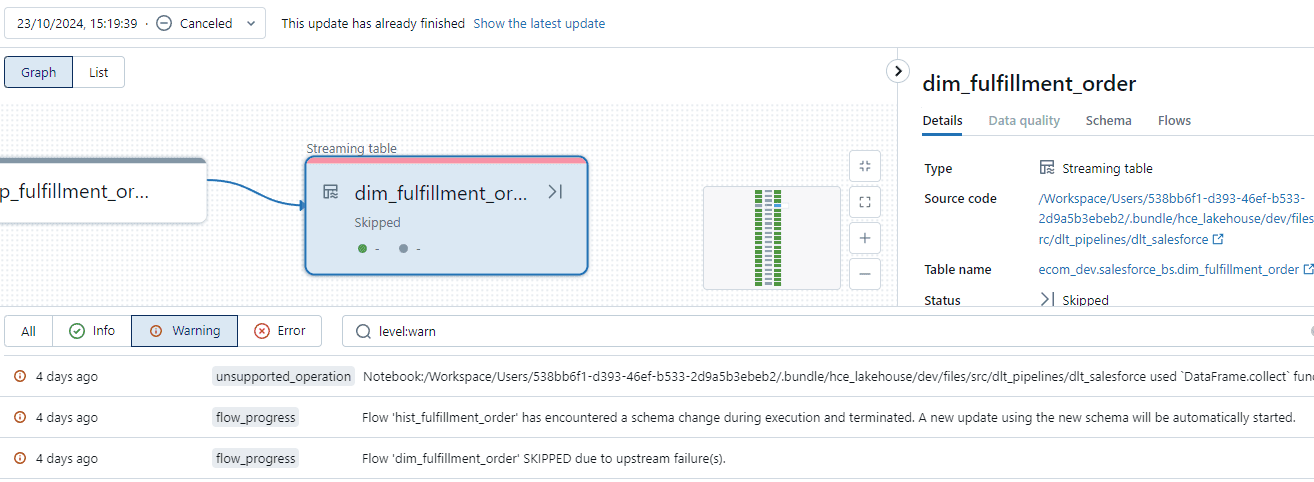
Otro punto importante es que DLT puede ser bastante exigente con el controlador, especialmente cuando se trata de muchas tablas y archivos. Esto puede dar lugar a tuberías DLT terriblemente lentas debido a problemas de recogida de basura, que se indican claramente en los registros (ver más abajo). Básicamente, el controlador necesita más memoria. Normalmente, utilizaríamos controladores pequeños y nodos trabajadores más grandes, pero, debido a la creciente complejidad en la optimización de consultas y la planificación DLT, esto está cambiando. Por tanto, asegúrate de que el controlador sea lo suficientemente grande como para poner a trabajar rápidamente a sus ejecutores. Escatimar en el controlador puede costarte más a largo plazo, ya que el trabajo puede tardar mucho más de lo esperado.

Una nota final sobre el autocargador. Lleva un registro de todos los archivos que ha cargado y no tiene en cuenta la fecha de modificación de los archivos. Así que si sobrescribes un archivo existente con algo nuevo, no tendrá ningún efecto en el DLT porque asumirá que ya ha cargado el archivo y lo ignorará. Esto puede ser bastante confuso si pones algunos datos nuevos en el almacenamiento y acabas sin nada nuevo en Databricks. Así que para los archivos nuevos, asegúrate de cambiar algo en el nombre/directorio del archivo para asegurarte de que se carga.
Eso es todo lo que tengo que compartir por ahora, ¡pero permanece atento! Estamos planeando más artículos para profundizar en cómo utilizamos los paquetes de activos Databricks para el despliegue y para proporcionar más detalles sobre nuestro marco de privacidad, incluyendo cómo protegemos las columnas PII, manejamos el consentimiento y gestionamos el derecho al olvido. Si necesitas ayuda con alguno de estos artículos, o tienes otras preguntas en el futuro, no dudes en ponerte en contacto con nosotros. ¡Feliz Ingeniería de Datos!

Antonio Rodríguez
Head of Data & AI
Data & AI
antonio.rodriguez@eraneos.com +34 610087105 | +34 914290584


