
Properly handling personally identifiable information (PII) is a huge challenge for any data platform. Realizing a fitting solution which is effective and manageable is hard. Topics that need to be considered include but are not limited to: knowing where PII is stored, data security, access management, retention, and the right to be forgotten. In this article, I will describe how we tackle some of these challenges within an e-commerce data platform. Our solution is inspired by the Databricks article Column-Level Encryption & PII Protection to which we added Delta Live Tables (DLT), Databricks native column level encryption, and dynamic views. The way we load data using DLT is described here and can be useful to read it before this article.
Our approach in a nutshell
- Maintaining configuration on PII columns from source systems which defines how to handle them and who has access.
- Enforcing this configuration in DLT pipelines before data is written to the bronze layer. This typically means nullifying unwanted PII and encrypting what we do want.
- Manage access, and possibly decryption of PII values for specific user groups, using Dynamic Views.
- Nullifying specific elements in the bronze layer and fully reloading downstream layers will enforce retention and the right to be forgotten.
Please note that the solution outlined in this article is one of many. Various factors, such as data volume, personal data types, and organizational complexity, must be considered when designing a suitable solution. Some solutions like Immuta integrate well with Databricks and do some of the heavy lifting related to privacy handling as well.
Protecting privacy using Delta Live Tables
The following section dives into implementation specifics of the points described above. An overview is provided in the diagram below showing how we load Salesforce data.
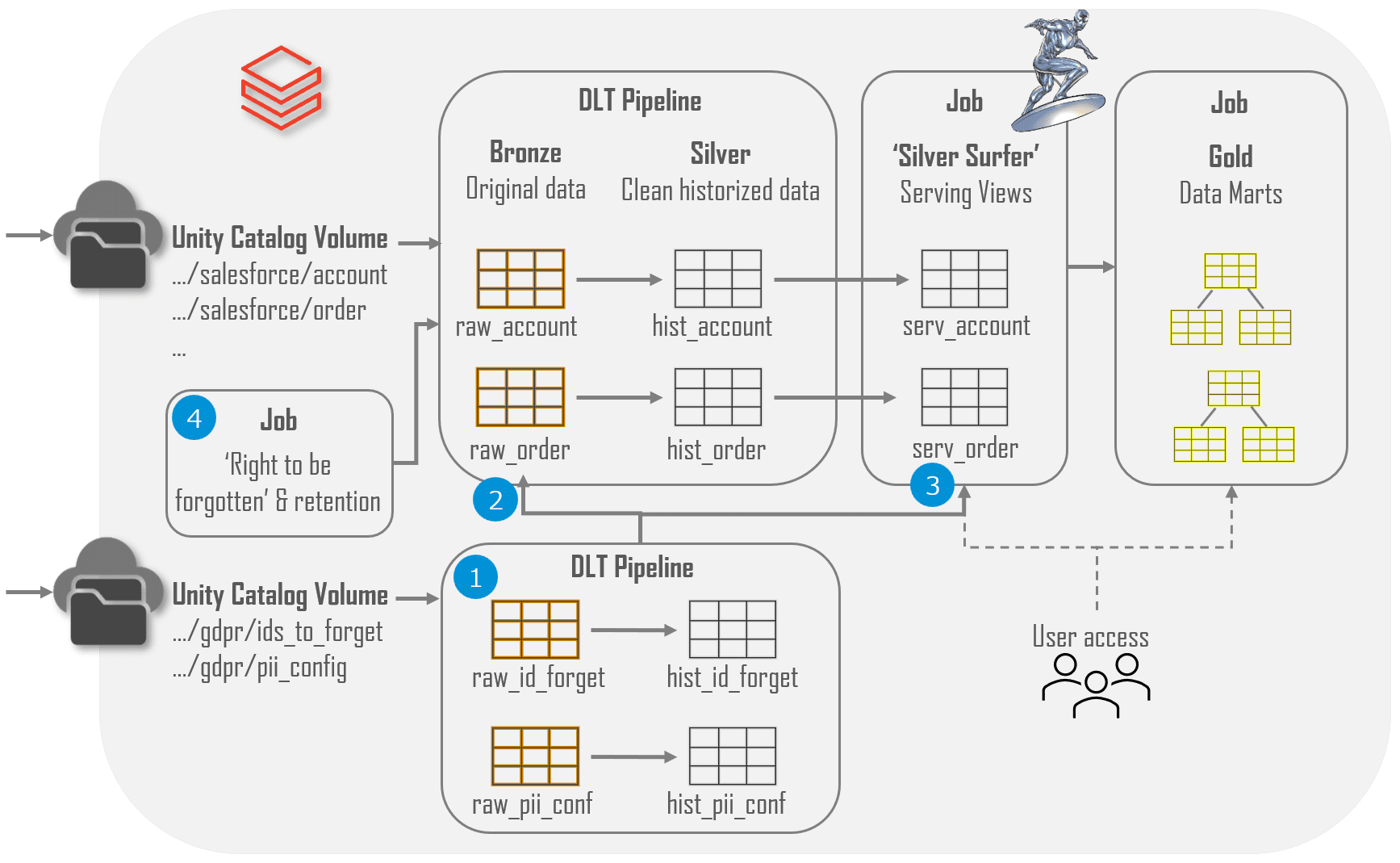
- The cornerstone of our implementation is a set of JSON configuration files containing the PII configuration and the ID’s of people who want to be forgotten. These are used throughout the data platform to properly handle PII data and are loaded into delta tables using its own DLT pipeline which tracks changes over time using SCD2 modelling.
- A Python module reads this configuration and applies it in DLT pipelines which load source specific data. This includes excluding PII values for which there is no consent and encrypting the remaining PII values.
- Access to silver data is managed via specific schemas containing dynamic views I have nick-named ‘Silver Surfer’. Users only have access to these views and the golden data but not to the bronze and silver tables directly.
- Execute a weekly job enforcing retention and the right to be forgotten in bronze tables. This job takes the configuration and NULLIFIES all PII columns for records older than the specified retention time or belonging to people who have exercised their right to be forgotten. All downstream tables are fully reloaded to propagate the NULL values across all data layers. It will take around 2 weeks for data to be really removed when including Delta retention and storage soft delete policies.
This design was chosen because it is simple compared to alternatives and suits DLT very well. Personal data is handled in a single place before the first layer and propagated from there. Admittedly this approach is computationally intensive as it requires full reloads from the bronze layer to handle the right to be forgotten and retention policies. Given the small data size (hundreds of millions of rows) this is not an issue and thus we value the simplicity of the approach over the additional running costs.
Common approaches split PII columns from the rest to make them easier to manage but this results in more tables, joins, and overall management which is not (yet) needed in our case. Pseudonymization, for example by hashing values, is also a popular approach However, since this operation can be reversed, it creates a false sense of security, and under GDPR, hashed values are still considered personal data.
PII Configuration
A set of JSON configuration, typically one per source system, define everything that needs to be done to be GDPR compliant. They are maintained in Git and describes all PII columns, how to handle each column and which groups may access it. As described in the DLT article each source system has its own DLT pipeline responsible for loading data into the bronze and silver tables. This DLT pipeline executes the following steps:
- Load the latest PII configuration as shown above from a Delta table
- Load the people without consent and those who executed their right to be forgotten from a Delta table
- Load all tables for a single source like Salesforce and use the PII configuration and consent information to remove and transform PII columns before writing the data into bronze tables (last lines in the screenshot below). For this we use a ‘privacy’ Python module we maintain and test separately.

The nullify without consent step nullifies all columns declared as PII in the config for those user IDs that we do not have consent / opt-in for or have exercised their ‘right to be forgotten’. This avoids unwanted data is (re) loaded into bronze tables.
The next transform by configuration step transforms all PII columns based on information specified in our PII configuration. In our implementation it means we NULLIFY unwanted columns and AES_ENCRYPT the PII elements we have consent for.
Because PII columns are encrypted in the bronze layer their encrypted values are automatically propagated to the silver layer and further. Thus all data access will return encrypted data unless explicitly decrypted; this is one way to achieve ‘privacy by default’. Unity Catalog’s lineage feature can be used to track where the PII columns are loaded. In theory, this lineage information could be used to decrypt columns in downstream tables. For example, the ‘billing_state’ in a golden dataset can be decrypted with the key used to encrypt BillingStateCode in bronze. This is the theory though as we currently do not yet use this method and lineage has not yet proven robust enough in all situations.
We use the encryption available in Databricks as it is easy to use and fast to execute. It can be noted that the downside of this method is that it does not preserve the input format as described in this article on Format Preserving Encryption.
PII Access
All access to data within Unity Catalog is handled by access groups scoped to schema level. We avoid access permissions on table or column level as much as possible in order to minimize management complexity. To facilitate this principle we add a specific ‘serving schema’ for each source which contains dynamic views used to access silver tables. Users only get access to these serving schemas and not to the schemas holding the actual tables. A concrete example is the salesforce_serve schema which contains access views for silver tables in salesforce schema maintained by the salesforce DLT pipeline.
These access views are created by a Databricks job which builds and executes a CREATE OR REPLACE VIEW statement based on table metadata and the PII configuration. So for the Salesforce Account table the view contains all columns from the table with some additional logic for PII columns. The BillingStateCode configured with AES encryption gets the following statement which allows specific groups to decrypt the value:
CASE WHEN is_account_group_member(‘allow_account_pii’) THEN AES_DECRYPT(BillingStateCode, SECRET(‘scope’, ‘secret_name’), ‘GCM’) ELSE BillingStateCode END AS BillingStateCode
Essentially only users member of the ‘allow_account_pii’ group will see the original value while all other users will get encrypted values. This group also has permission to get secrets from the Secret Scope or else the decryption will fail. This job is executed after every load to allow serving views to adapt for schema evolution of source tables.
Apart from this logic in the dynamic views the groups also need read/select access to the serving schemas. These permissions are managed in Unity Catalog and there are different approaches to do this. Our current approach is quite liberal as it allows large sets of users to access the serving schemas by default. We rely on the dynamic logic to provide column level access.
Column Masking in Databricks could also be used for this was not yet supported for tables maintained by Delta Live Tables when we did the implementation. Now it seems to be in public preview for streaming tables and materialized views so worth looking into.
Apart for data access the ‘Silver Surfer’ layer can also be used to provide a clean and stable layer to consumers of silver data. Data standardization and column renames for example can be handled here to avoid all consumers having to deal with these kinds of issues. You could do all kinds of tricks here although I would keep it source aligned and do business translation in the golden layer.
Retention and the Right to be Forgotten (RTBF)
Data retention and the RTBF are closely related as the implementation nullifies PII columns for certain records. For efficiency purposes we do both in a single job which we execute once per week. This job uses the PII configuration and list of account ids which want to be forgotten to build UPDATE statements for bronze tables. For the Salesforce Account table it becomes something like the following but this varies per source. The Id’s to forget are located in another dataset provided to the platform and ‘retention in days’ is configured per table.
UPDATE raw_account SET BillingStateCode = NULL, <other PII columns> WHERE Id IN (<list of ID’s to forget>) OR LastModifiedDate < DATE_ADD(NOW(), -1* <retention in days>)
Once this job is done the DLT pipeline is started using the API with a Full refresh on all silver tables containing PII. The golden layer, in our case modelled dimensionally, needs to be reloaded as well. This is done by replacing the tables and refreshing Materialized Views. Data will truly be removed after a two weeks when taking Delta retention and storage soft delete into account.
Depending on data sizes this can be very expensive but given the small volumes it is acceptable in our case. The upside is that the solution is foul proof and cheap to maintain as it avoids tracking and deleting PII data across all layers. When volumes are big it can help to separate PII into smaller tables in the bronze layer which are cheaper to update and propagate.
Lessons learned
Overall, we are highly satisfied with the current solution, primarily due to its simplicity. PII protection and data retention are managed within the bronze layer through configuration. Access control and decryption are handled via easy to manage VIEWS in the ‘Silver Surfer’ layer. The actual Python module responsible for most of the processing consists of only 600 lines of code. However, there are also some disadvantages and lessons learned worth sharing.
The Silver Surfer layer requires maintenance and we have to adapt for schema evolution of source tables. As a consequence, we have to update the entire layer after every load even when nothing has changed. Sometimes we remove tables from sources as well and are left with orphaned views which we need to remove. Overall not hard to do but still is a bit of management we need to take care of.
The source of the Delta Live Tables, typically a storage location holding raw files, also has to be considered as it may contain (unwanted) PII data as well. In our solution we clean this location using storage Data Lifecycle Management (DLM) rules. This means we can never do a DLT Full Refresh on the bronze layer and we have disabled this option for those tables by setting ‘pipelines.reset.allowed’ to ‘false’. As a consequence, we are limited in the changes we can make to those tables as we cannot easily reload historical data. Overall the bronze layer is not intended to make any changes to the data but still it is something to be aware of.


